
EFI - Enzyme Similarity Tool
EFI-EST and Cytoscape Tutorials
Node Attributes
A major advantage of sequence similarity networks is the ability to include pertinent information for each individual protein (such as species, annotation, length, PDB deposition, etc.). This information is included as “Node Attributes” which are searchable and sortable within the data panel in a sequence similarity network displayed in Cytoscape (see Figure 3 here).
Also notice that if you right click (control+click on Mac) on any node in a network open in Cytoscape, you will get a sub-menu to carry out node-specific actions or access external links via LinkOut, such as to UniProtKB.
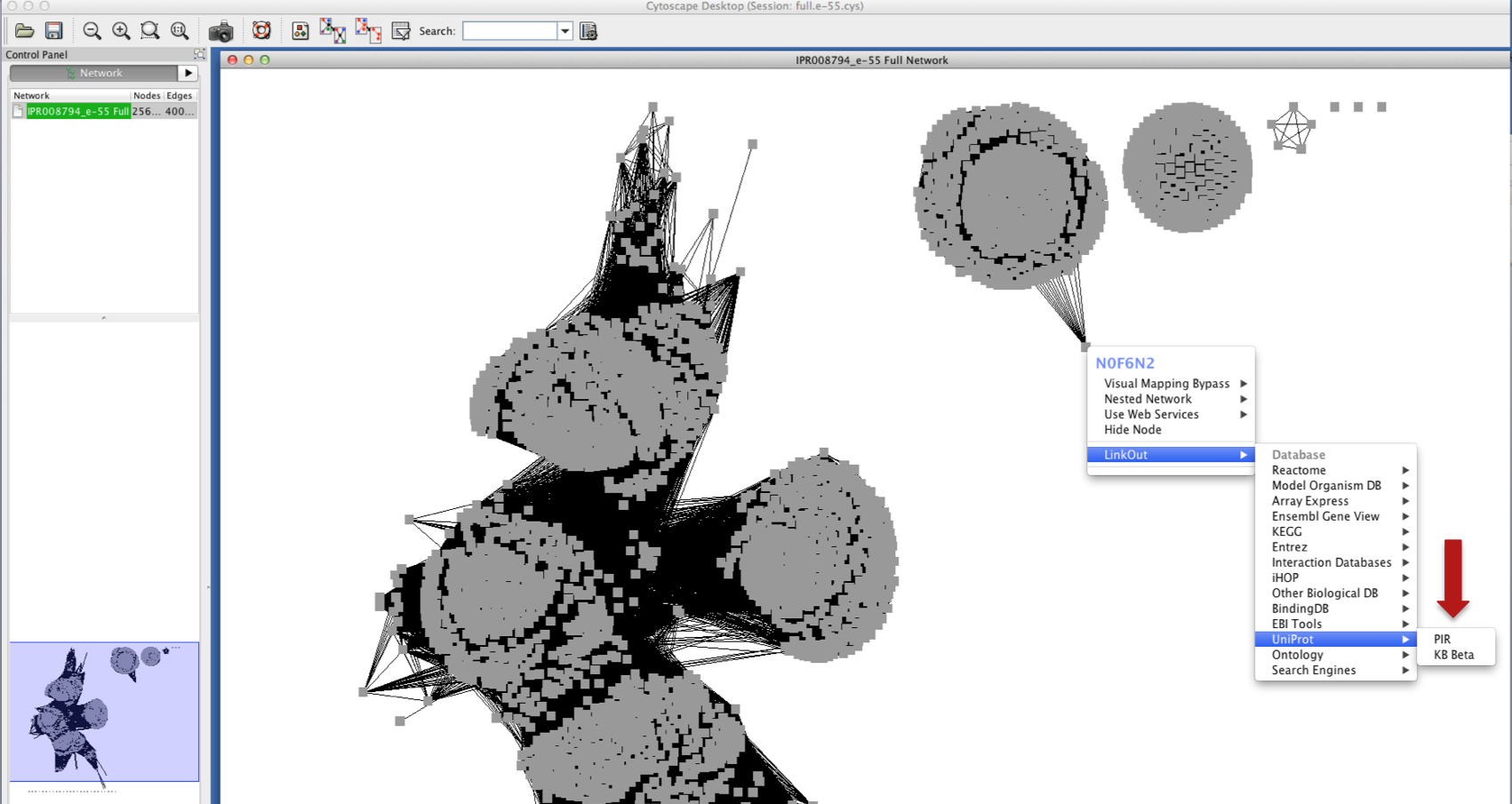
Note that the EFI-EST web server uses data available in the UniProtKB database to populate node attribute fields. Therefore, only information that is stored in UniProtKB is included in EFI-EST networks. Additional node attributes can be added within Cytoscape by using the BridgeDB add-on. Adding your own node attributes is useful for mapping annotations or other information that you have at hand, which is otherwise not available in UniProtKB.
An introduction on how to use Cytoscape can be found here.
Difference node attributes are available for the various EFI-EST options:
- Node attributes for EFI-EST Options A-D, with FASTA header reading for Option C
- Node attributes for EFI-EST Color SSN utility if an SSN was generated using Options A-D, with FASTA header reading for Option C
- Node attributes for EFI-EST Option C without FASTA header reading and Color SSN utility if Option C without FASTA header reading was used as input
Node Attributes for EFI-EST Options A-D
| Node Attribute | Description - Options A, B, C with FASTA header reading, D |
|---|---|
| Name | Full network - UniProt accession; Rep Node network - UniProt accession for the longest sequence in the representative node (seed sequence for CD-Hit) |
| Shared name | Full network - UniProt accession; Rep Node network - UniProt accession for the longest sequence in the representative node (seed sequence for CD-Hit) |
| Number of IDs in Rep Node1 | Number of UniProt IDs in the representative node |
| List of IDs in Rep Node1 | List of UniProt IDs in the representative node |
| Sequence Source | Options B, C, and D, “USER” if from user-supplied file, “FAMILY” if from user-specified Pfam/InterPro family, “USER+FAMILY” if from both |
| Query IDs | Options C and D, Input Query ID(s) that identified a UniProt match in the idmapping file |
| Other IDs | Option C, headers for FASTA sequences that could not identify a UniProt match in the idmapping file |
| Cluster Number | Number assigned to cluster, in order of decreasing number of sequences in the clusters (“999999” for singletons) |
| Cluster Sequence Count | Number of sequences in the cluster |
| Node.fillColor | Unique color assigned to cluster, in hexadecimal |
| Organism | organism genus/genera and species, from UniProt taxonomy.xml |
| Taxonomy ID | NCBI taxonomy identifier(s), from UniProt |
| UniProt Annotation Stastus | SwissProt - manually annotated; TrEMBL - automatically annotated; from UniProt |
| Description | protein name(s)/annotation(s), from UniProtKB |
| SwissProt Description | protein name(s)/annotation(s), from UniProtKB for SwissProt reviewed entries |
| Sequence Length | number(s) of amino acid residues, from UniProt |
| Gene name | gene name(s) |
| NCBI IDs | RefSeq/GenBank IDs and GI numbers, from UniProt idmapping |
| Superkingdom | domain of life of the organism, from UniProt taxonomy.xml |
| Kingdom | kingdom of the organism, from UniProt taxonomy.xml |
| Phylum | Phylogenetic phylum of the organism, from UniProt taxonomy.xml |
| Class | Phylogenetic class of the organism, from UniProt taxonomy.xml |
| Order | Phylogenetic order of the organism, from UniProt taxonomy.xml |
| Family | Phylogenetic family of the organism, from UniProt taxonomy.xml |
| Genus | Phylogenetic genus of the organism, from UniProt taxonomy.xml |
| Species | Phylogenetic species of the organism, from UniProt taxonomy.xml |
| EC | EC number, from UniProt |
| PFAM | Pfam family, from UniProt |
| IPRO | InterPro family, from UniProt |
| PDB | Protein Data Bank entry, from UniProt |
| BRENDA ID | BRENDA Database ID, from UniProt |
| CAZY Name | Carbohydrate-Active enZYmes (CAZy) family name(s), from UniProt |
| GO Term | Gene Ontology classification(s), from UniProt |
| KEGG ID | KEGG Database ID, from UniProt |
| PATRIC ID | PATRIC Database ID, from UniProt |
| STRING ID | STRING Database ID, from UniProt |
| HMP Body Site | location(s) of organism(s) in/on the body, if human microbiome organism, spreadsheet from HMP |
| HMP Oxygen | oxygen requirement(s), if human microbiome organism, spreadsheet from HMP |
| P01 gDNA | availability of gDNA(s) at EFI Protein Core, custom |
Node Attributes for EFI-EST Color SSN Utility
| Node Attribute | Description - Options A, B, C with FASTA header reading, D |
|---|---|
| Name | Full network - UniProt accession; Rep Node network - UniProt accession for the longest sequence in the representative node (seed sequence for CD-Hit) |
| Shared name | Full network - UniProt accession; Rep Node network - UniProt accession for the longest sequence in the representative node (seed sequence for CD-Hit) |
| Number of IDs in Rep Node1 | Number of UniProt IDs in the representative node |
| List of IDs in Rep Node1 | List of UniProt IDs in the representative node |
| Sequence Source | Options B, C, and D, “USER” if from user-supplied file, “FAMILY” if from user-specified Pfam/InterPro family, “USER+FAMILY” if from both |
| Query IDs | Options C and D, Input Query ID(s) that identified a UniProt match in the idmapping file |
| Other IDs | Option C, headers for FASTA sequences that could not identify a UniProt match in the idmapping file |
| Cluster Number | Number assigned to cluster, in order of decreasing number of sequences in the clusters (“999999” for singletons) |
| Cluster Sequence Count | Number of sequences in the cluster |
| Node.fillColor | Unique color assigned to cluster, in hexadecimal |
| Organism | organism genus/genera and species, from UniProt taxonomy.xml |
| Taxonomy ID | NCBI taxonomy identifier(s), from UniProt |
| UniProt Annotation Stastus | SwissProt - manually annotated; TrEMBL - automatically annotated; from UniProt |
| Description | protein name(s)/annotation(s), from UniProtKB |
| SwissProt Description | protein name(s)/annotation(s), from UniProtKB for SwissProt reviewed entries |
| Sequence Length | number(s) of amino acid residues, from UniProt |
| Gene name | gene name(s) |
| NCBI IDs | RefSeq/GenBank IDs and GI numbers, from UniProt idmapping |
| Superkingdom | domain of life of the organism, from UniProt taxonomy.xml |
| Kingdom | kingdom of the organism, from UniProt taxonomy.xml |
| Phylum | Phylogenetic phylum of the organism, from UniProt taxonomy.xml |
| Class | Phylogenetic class of the organism, from UniProt taxonomy.xml |
| Order | Phylogenetic order of the organism, from UniProt taxonomy.xml |
| Family | Phylogenetic family of the organism, from UniProt taxonomy.xml |
| Genus | Phylogenetic genus of the organism, from UniProt taxonomy.xml |
| Species | Phylogenetic species of the organism, from UniProt taxonomy.xml |
| EC | EC number, from UniProt |
| PFAM | Pfam family, from UniProt |
| IPRO | InterPro family, from UniProt |
| PDB | Protein Data Bank entry, from UniProt |
| BRENDA ID | BRENDA Database ID, from UniProt |
| CAZY Name | Carbohydrate-Active enZYmes (CAZy) family name(s), from UniProt |
| GO Term | Gene Ontology classification(s), from UniProt |
| KEGG ID | KEGG Database ID, from UniProt |
| PATRIC ID | PATRIC Database ID, from UniProt |
| STRING ID | STRING Database ID, from UniProt |
| HMP Body Site | location(s) of organism(s) in/on the body, if human microbiome organism, spreadsheet from HMP |
| HMP Oxygen | oxygen requirement(s), if human microbiome organism, spreadsheet from HMP |
| P01 gDNA | availability of gDNA(s) at EFI Protein Core, custom |
Node Attributes for EFI-EST Option C and Color SSN Utility without FASTA header reading
| Node Attribute | Description - Option C without FASTA header reading |
|---|---|
| Name | zzznnn, where nnn = number of the sequence in FASTA file |
| Shared Name | zzznnn, where nnn = number of the sequence in FASTA file |
| Description | FASTA Header |
| Sequence Length | Length of sequence in FASTA entry |
Click here to contact us for help, reporting issues, or suggestions.
University of Illinois at Urbana-Champaign
1206 W. Gregory Drive Urbana, IL 61801
efi@enzymefunction.org
